计算机组成与体系结构
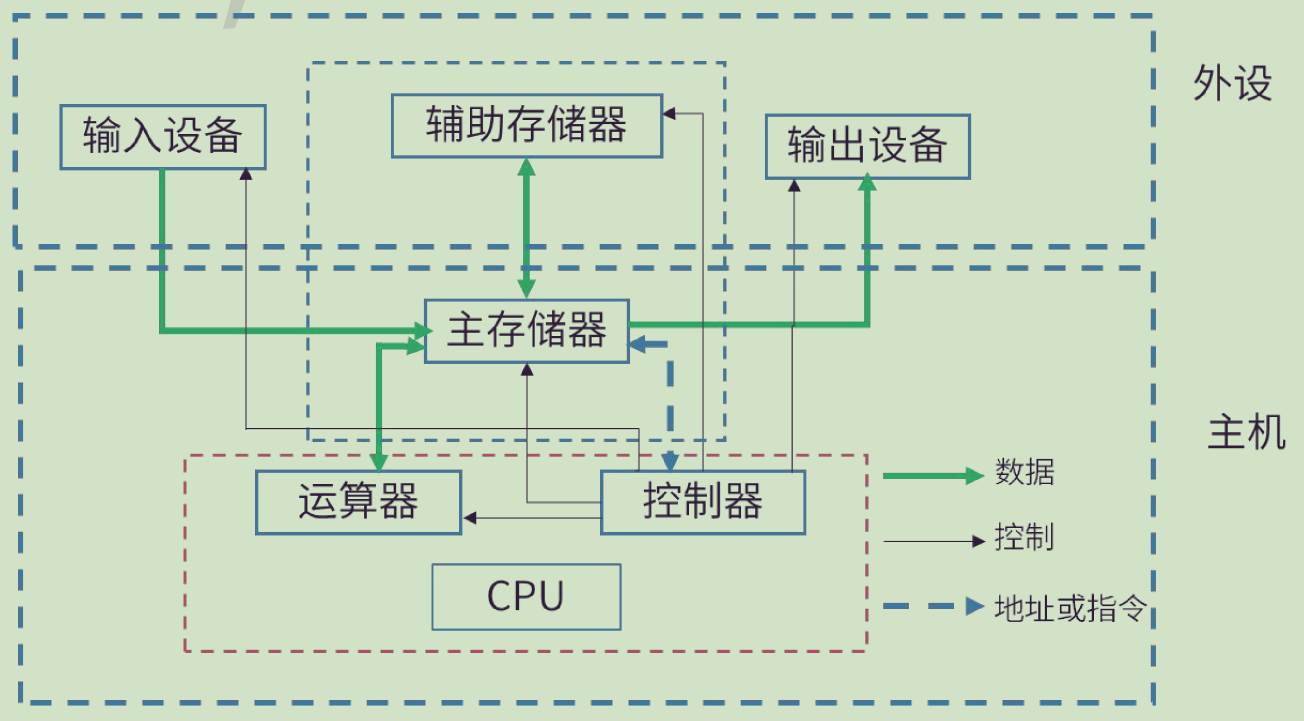
计算机硬件组成
CPU 的主频、倍频、外频
- 主频即 CPU 的时钟频率,计算机的操作在时钟信号的控制下分步执行,每个时钟信号周期完成一步操作,时钟频率的高低在很大程度上反映了 CPU 速度的快慢
- 外频就是外部频率,指的是系统系统总线的频率
- 倍频的全程是倍频系数,倍频系数是 CPU 主频与外频之间的相对比例关系。它的作用是使系统总线工作在相对较低的频率上,而 CPU 可以通过倍频来提升
总线
一条总线同一时刻仅允许一个设备发送,但允许多个设备接收。所以总线是半双工模式
提示
半双工(Half Duplex)是一种传送制式。使用同一根传输线既作接收又作发送,数据可以在两个方向上传送,但通信双方不能同时收发数据,这种传送方式就是半双工制
全双工模式(Full Duplex),是指当数据的发送和接收分流,分别由两根不同的传输线传送时,通信双方都能在同一时刻进行发送和接收操作的传送方式
对于全双工和半双工的经典举例一般就是电话和对讲机
长距离传输适合使用串行总线(不确定那一条的数据先到);短距离适合使用并行总线
总线的分类
- 数据总线(DB,Data Bus):在 CPU 与 RAM 之间来回传送需要处理或是需要存储的数据
- 地址总线(AB,Address Bus):用来指定在 RAM(Random Access Memory)之中存储的数据的地址
- 控制总线(CB,Control Bus):将微处理器控制单元(Control Unit)的信号传送到周边设备
计算机体系结构
Flynn 分类法
| 体系结构类型 | 结构 | 关键特性 | 代表 |
|---|---|---|---|
| 单指令单数据流 SISD (Single instruction, Single data) | 控制部分:一个 处理器:一个 主存模块:一个 | 单处理器系统 | |
| 单指令多数据流 SIMD (Single instruction, Multiple data) | 控制部分:一个 处理器:多个 主存模块:多个 | 各处理器以异步的形式执行同一条指令 | 并行处理机阵列处理机超级向量处理机 |
| 多指令单数据流 MISD (Multiple instruction, Single data) | 控制部分:多个 处理器:一个 主存模块:多个 | 被证明不可能,至少是不实际 | 目前没有,有文献成流水线计算机为此类 |
| 多指令多数据流 MIMD (Multiple instruction, Multiple data) | 控制部分:多个 处理器:多个 主存模块:多个 | 能够实现作业、任务、指令等各级全面并行 | 多计算机系统 多计算机 |
CISC 与 RISC
| 指令系统类型 | 复杂指令集计算机(CISC,Complex Instruction Set Computers) | 精简指令集计算机(RISC,Reduced Instruction Set Computers) |
|---|---|---|
| 指令 | 数量多,使用频率差别大,可变长格式 | 数量少,使用频率接近,定长格式,大部分为单周期指令,操作寄存器,只有 Load/Store 操作内存 |
| 寻址方式 | 支持多种 | 支持方式少 |
| 实现方式 | 微程序控制技术(微码) | 增加了通用寄存器;硬布线逻辑控制为主;适合采用流水线 |
| 其他 | 研制周期长 | 优化编译,有效支持高级语言 |
冯·若依曼结构与哈佛结构
冯·若依曼结构
冯·若依曼结构也称普林斯顿结构,是一种将程序指令存储器和数据存储器合并在一起的存储结构
特点
- 一般用于 PC 处理器,如 I3、I5、I7 处理器
- 指令与数据存储器合并在一起
- 指令与数据都通过相同的数据总线传输
哈弗结构
哈佛结构是一种程序指令和数据存储分开的存储器结构。哈佛结构是一种并行体系结构,它的主要特点是将程序和数据存储在不同的存储器空间中,即程序存储器和数据存储器是两个独立的存储器,每个存储器独立编址、独立访问
特点
- 一般用于嵌入式相同处理器(DSP)
- 指令与数据分开存储,可以并行读取,有较高的数据吞吐率
- 有 4 条总线:指令和数据的数据总线与地址总线
DSP:数字信号处理,Digital Signal Processing
存储系统
层次化存储结构
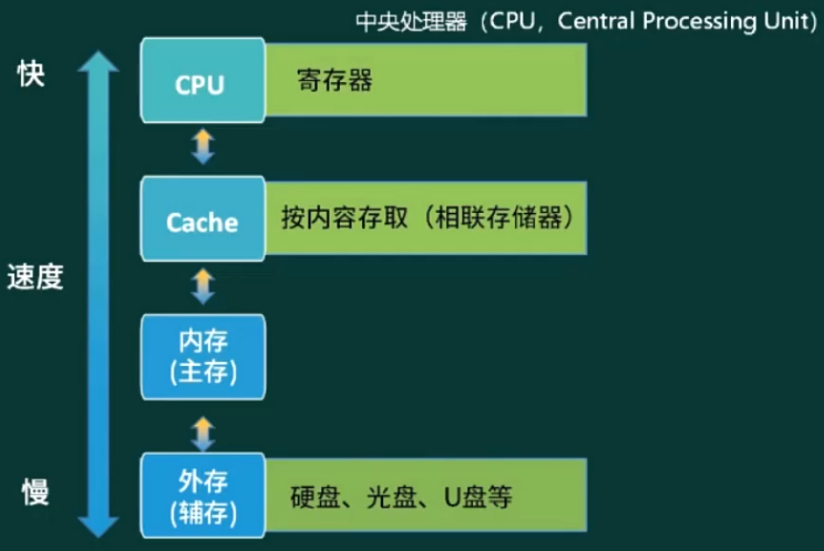
局部性原理
- 时间局部性:指程序种某指令一旦执行,不久以后该指令可能再次执行。典型原因是由于程序中存在者大量的循环操作
- 空间局部性:指一旦程序访问了某个存储单元,不久之后,其附近的存储单元也将被访问,即程序在一段时间内所访问的地址可能集中在一定的范围内。其典型情况是程序顺序执行
- 局部性理论是层次化存储结构的支撑
- 工作集理论:工作集是进程运行时被频繁访问的页面集合
高速缓存(Cache)
- Cache 的功能:提高 CPU 数据输入输出的速率,突破冯·诺依曼瓶颈,即 CPU 与存储系统间数据传输带宽限制。
- 在计算机的存储系统体系中,Cache 是访问速度最快的层次(除寄存器以外)
- 使用 Cache 改善系统性能的依据是程序的局部性原理
- 如果以 h 代表 Cache 的访问命中率,t1表示 Cache 的周期时间,t2表示主存储器周期时间,以读操作为例,使用"Cache+主存储器"的系统的平均周期为 t3,则:
- Cache 对与开发人员是透明的,一般用不到,但内外存、寄存器这些都是可以访问的(高速缓存是由硬件自动完成的)
主存/内存
分类
- 相联存储器
- 按内容存取,如 Cache
- 随机存取存储器(RAM,Random Access Memory)
- DRAM(Dynamic RAM,动态 RAM)-> SDRAM(带同步机制的 DRAM)
- SRAM(Static RAM,静态 RAM)
- 只读存储器(ROM,Read-Only Memory)
- MROM(Mask ROM,掩模式 ROM)
- PROM(Programmable ROM,一次可编程 ROM)
- EPROM(Erasable PROM,可擦除的 PROM)
- 闪速存储器(flash memory,闪存)
BIOS 使用 ROM
编址计算

- 存储单元个数计算:最大地址 + 1 - 最小地址
- 内存总容量 = 存储单元个数 * 编址内容
- 按字节(1 字节(B) = 8bit)编址,存储单元数 * 8bit
- 按字编址,存储单元数 * 机器字长
- 总容量 = 单位芯片容量 * 芯片个数
- 已知芯片单位容量,求所用芯片的片数,总容量/单位容量
- 已知所用芯片的片数,求取芯片单位容量,总容量/芯片片数
磁盘结构与参数

- 存取时间 = 寻道时间 + 等待时间(平均定位时间 + 转动延迟)
- 寻道时间是指磁头移动到磁道所需的时间
- 等待时间为等待读写的扇区转到磁头下方所用的时间(有时还需要加上数据的传输时间)
- 在处理过程中,如果有关于缓冲区的使用,需要了解对于单缓冲区每次只能被一个进程使用,即向缓冲区传输数据的时候不能从缓冲区读取数据,反之亦然
- 对于磁盘存储的优化,是因为磁头保持转动的状态,当读取数据传输或处理时,磁头会移动到超前的位置,需要继续旋转才能回到逻辑下一磁盘块,优化存储就是调整磁盘块的位置,让逻辑下一磁盘块放到磁头将要开始读取该逻辑块的位置
磁盘移臂调度算法
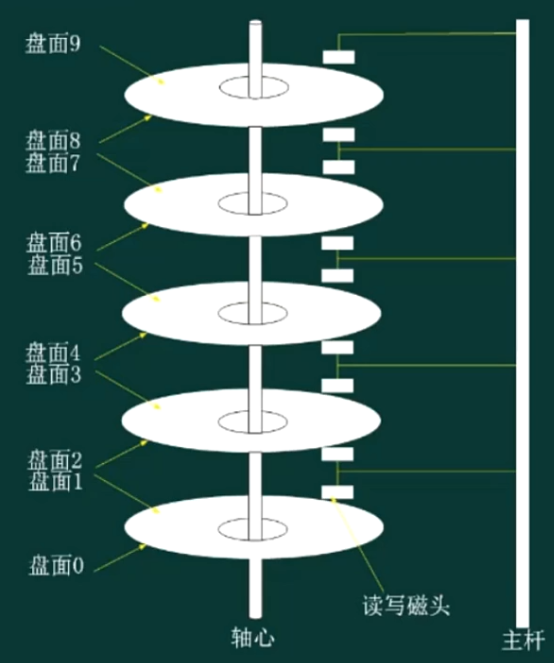
- 先来先服务(FCFS,First Come,First Served):谁先申请先服务谁
- 最短寻道时间优先(SSTF,Shortest Seek Time First):申请时判断与磁头当前位置的距离,谁短先服务谁
- 扫描算法 SCAN:也叫电梯算法,将盘面看作电梯楼层,每次单方向运动,如同电梯上楼下楼,双向扫描
- 循环扫描 CSCAN:单向扫描。类比水井打水的过程,每次都将水桶丢回井底,打满再拉上来
流水线技术
概念
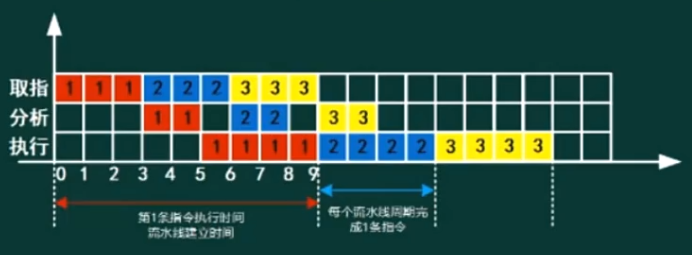
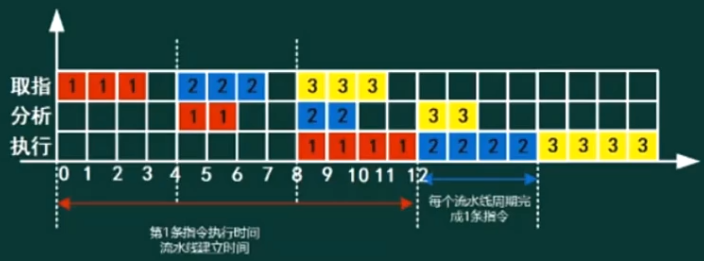
流水线是指在程序执行时多条指令重叠进行操作的一种准并行处理实现技术。各种部件同时处理是针对不同指令而言的,它们可同时为多条指令的不同部分进行工作,以提高各部件的利用率和指令的平均执行速度
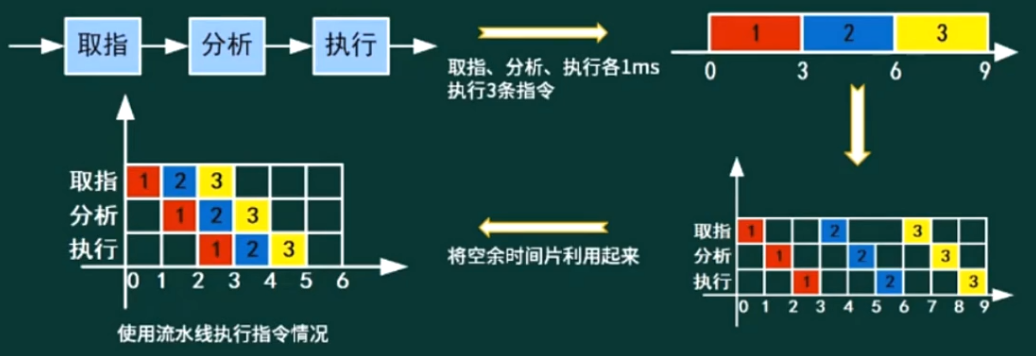
流水线计算
- 流水线建立时间:一条指令执行时间
- 流水线周期:执行时间最长的一段(最长的执行时间其实就是流水线的瓶颈所在)
流水线计算公式
- 理论公式
流水线技术-流水线计算-理论公式 - 实践公式
流水线技术-流水线计算-实践公式 - 流水线吞吐率(TP,Throughput rate):指在
单位时间内流水线所完成的任务数量或输出的结果数量 - 流水线最大吞吐率(即流水线周期的倒数)
- 流水线加速比:不使用流水线所用时间和使用流水线所用时间的比值(简记:加速比一般是大于 1 的,所以大值是分子)
缓存区问题
一般来说,缓存区问题都是有三个步骤
- 读入缓存区,花费时间 a
- 送入用户区, 花费时间 b
- 处理数据,花费时间 c
对于单缓存区来说,同一时刻只能对缓存区做一个操作,要么存要么取,所以可以将存(读入缓存区)/取(送入用户区)这两步看成是一个整体,构成流水线的第一部分,剩下的构成第二部分,这个流水线执行 n 次的时间是
对于双缓存区来说,就可以并行操作缓存区了(从第一个缓存区读出和从第二个缓存区送入用户区),所以相当于读入缓存区、送入用户区和处理数据变成了流水线中的各个步骤,这个流水线的执行 n 次的时间是
超标量流水线

简单来说,就是多个流水线并行处理。假设有 n 条指令,有 m 组流水线,执行时间为(理论公式)
校验码
奇偶校验
奇偶校验码的编码方式是:由若干位有效信息(如一个字节),再加上一个二进制位(校验位)组成校验码
- 奇校验:整个校验码(有效信息位和校验位)中"1"的个数位奇数
- 偶校验:整个校验码(有效信息位和校验位)中"1"的个数位偶数
奇偶校验,可检查奇数位的错误,不可纠错
循环冗余校验码
循环冗余校验(Cyclic Redundancy Check,CRC)的基本原理是:在 K 位信息码后再添加 R 位的校验码,整个编码长度为 N 位,因此,这种编码又称(N,K)码。对于一个给定的(N,K)码,可以证明存在一个最高次幂为的多项式 。根据可以生成 R 位的校验码,而叫作这个 CRC 码的生成多项式。
校验码的具体生成过程为:假设发送信息用信息多项式表示,将左移 R 位,则可表示成,这样的右边就会空出 R 位,这就是校验码的位置。通过除以生成多项式得到的余数就是校验码。
CRC 码的生成步骤为:
- 将的最高幂次为 R 的生成多项式转换成对应的 R+1 位二进制数
- 将信息码左移 R 位,相当于对应的信息多项式$C(x)×2R $
- 用生成多项式(二进制数)对信息码做模 2 除,得到 R 位的余数
- 将余数拼到信息码左移后空出的位置,得到完整的 CRC 码
CRC 校验,可检错,不可纠错
提示
- 生成多项式:形如的式子,从它得到的二进制数是
10011,就是多项式的每一项的系数 - 模 2 除:是指在做除法运算的过程中不计其进位/借位的除法,也可以用异或运算,同为 0,异为 1
- R 的位数就是多项式的最高次幂,或者多项式得到的二进制数的位数-1
例:原始报文位"10111",其生成多项为。对其进行 CRC 编码后的结果为?
- 根据生成多项式得到二进制数:1011
- 模 2 除[1]得到余数为 011(余数不够,高位补 0)
- 最终的得到的 CRC 码为 10111011
海明校验码
海明校验码的原理是:在有效信息位中加入几个校验位形成海明码,使码距比较均匀地拉大,并把海明校验码的每个二进制位分配到几个奇偶校验组中。当某一位出错后,就会引起有关几个校验位的值发生变化,这不但可以发现错误,还能指出错误的位置,为自动纠错提供了依据
嵌入式系统
芯片
DSP
DSP 芯片,也称数字信号处理器,是一种特别适合进行数字信号处理运算的微处理器,其主要应用是实时地实现各种数字信号处理算法
SoC
系统级芯片,也称片上系统(System on Chip,SoC)。从狭义角度讲,它是信息系统核心的芯片集成,是将系统关键部件集成在一块芯片上;从广义角度讲,SoC 是一个微小型系统,如果说中央处理器(CPU)是大脑,那么 SoC 就是包括大脑、心脏、眼睛和手的系统
有专用目标的集成电路
MPU
微机中的中央处理器(Center Process Unit,CPU)称为微处理器(Microprocessor Unit,MPU),是构成微机的核心部件,也可以说是微机的心脏。它起到控制整个微型计算机工作的作用,产生控制信号对相应的部件进行控制,并执行相应的操作
MPU 在工作温度、电磁兼容性以及可靠性等方面的要求较通用的标准的微处理器高,但是在功能方面与标准的微处理器基本上是一样的
MCU
微控制单元(Microcontroller Unit,MCU)又称单片微型计算机(Single Chip Microcomputer)或单片机,是把中央处理器的频率与规格做适当缩减,并将内存(Memory)、计数器(Timer)、USB、A/D 转换、UART、PLC、DMA 等周边接口,甚至 LCD 驱动电路都整合在单一芯片上,形成芯片级的计算机,为不同的应用场合做不同组合控制
交叉开发环境
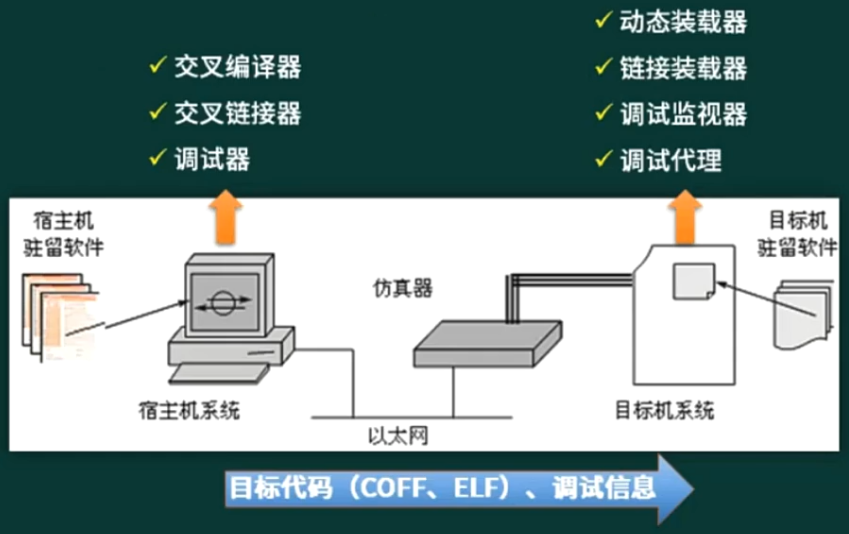
初始化过程
片级初始化 → 板级初始化 → 系统初始化
- 片级初始化:
完成嵌入式微处理器的初始化,包括设置嵌入式微处理器的核心寄存器和控制寄存器、嵌入式微处理核心工作模式和嵌入式微处理器的局部总线模式等。片级初始化把嵌入式微处理器从上电时的默认状态逐步设置成系统所要求的工作状态。这是一个纯硬件的初始化过程 - 板级初始化:完成嵌入式微处理器以外的
其他硬件设备的初始化。另外,还需要设置某些软件的数据结构和参数,为随后的系统级初始化和应用程序的运行建立硬件和软件环境。这是一个同时包含软硬件两部分在内的初始化过程 - 系统初始化:该初始化过程
以软件初始化为主,主要进行操作系统的初始化,BSP 将对嵌入式微处理器的控制权转交给嵌入式系统,由操作系统完成余下的初始化操作,包含加载和初始化与硬件无关的设备驱动程序,建立系统内存区,加载并初始化其他系统软件模块,如网络系统,文件系统等。最后,操作系统创建应用程序环境,并将控制权交给应用程序的入口
假设这个 n 次方根号是个除法符号 ↩︎